

Our Data Services
Data Collection Services
TagX offers tailored data collection services across industries like automotive, finance, retail, and healthcare. We deliver accurate, timely, and relevant data to support data-driven decisions and business growth.
Data Cleaning and Validation
We provide data cleaning and validation services to ensure accuracy and reliability. Our team removes redundancies and corrects errors, ensuring your data is ready for actionable insights and informed decisions.
Custom Data Solutions
TagX provides custom data solutions tailored to your business needs. We offer specialized data sets, custom APIs, and bespoke strategies, ensuring accurate, actionable data that drives growth and innovation.
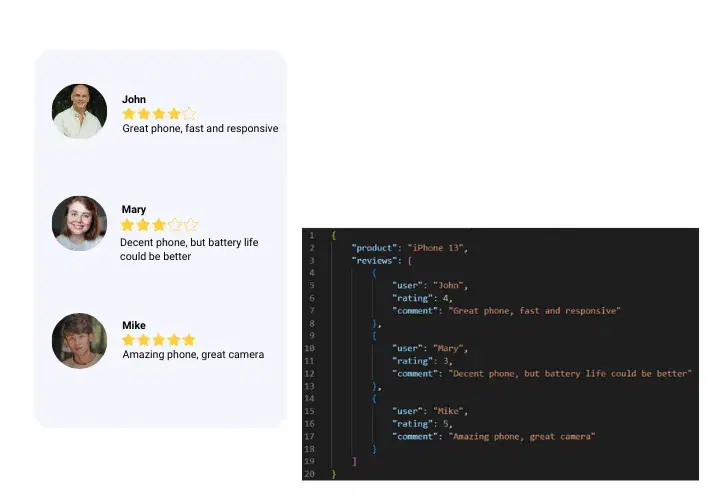
Web Scraping Services
Our web scraping services offer real-time, structured data extraction from any website. We provide scalable solutions, including custom APIs, to help businesses automate data collection and stay competitive.
Data API Development
We specialize in custom data API development to integrate real-time data into your systems. Our secure APIs streamline workflows and enhance decision-making, supporting a wide range of industry needs.
Social Media Data Extraction
TagX extracts valuable social media data, including user engagement and sentiment, to inform marketing strategies and customer insights. We provide real-time, tailored data for improved decision-making.
Real Estate Data Extraction
We specialize in real estate data extraction, including property listings, market trends, and demographic insights. Our data supports better investment decisions and enhances property management strategies.
Financial Data Sourcing
TagX’s financial data sourcing gathers relevant market trends and economic indicators to inform investment decisions, risk assessments, and financial planning, providing real-time, actionable insights.
E-commerce Data Collection
We gather comprehensive e-commerce data, including product listings, reviews, and pricing. Our insights help optimize inventory, marketing, and pricing strategies, empowering businesses in the competitive e-commerce landscape.
Customer Feedback Analysis
We analyze customer feedback from various channels to provide actionable insights. Our data helps businesses understand preferences, pain points, and make informed decisions to enhance products and services.
Competitor Pricing Analysis
We collect and analyze competitor pricing data to help businesses understand market trends, identify pricing opportunities, and position their products effectively for growth and profitability.
Public Records Data Acquisition
TagX provides access to essential public records data, including property records and court documents. Our data enhances research and decision-making, supporting informed choices across various industries.
Industries We Serve
Automotive
Banking and Finance
Real Estate
Transportation and Logistics
Insurance

Workflow
How it Works?
At TagX, we kick off the process by thoroughly understanding your specific needs and objectives. We engage in detailed discussions to identify the types of data required, the sources to target, and any particular formats or standards for the final dataset.
At TagX, we specialize in providing a robust web scraping API that streamlines the data extraction process. Leveraging our expertise, TagX develops custom APIs and scripts tailored to your specific requirements, ensuring that the data collection process aligns perfectly with your business needs. With our web scraping API, you can automate data collection, gain valuable insights, and drive data-driven decisions with ease.
With state-of-the-art web scraping tools, TagX meticulously extracts data from various sources. Our approach focuses on accuracy and comprehensiveness, gathering real-time information that aligns perfectly with your project needs.
After extraction, we employ rigorous data cleaning and standardization techniques at TagX. This critical step ensures that your dataset is free from duplicates and errors, delivering a reliable foundation for analysis.
Finally, TagX delivers the cleaned and structured dataset in your preferred format. With a commitment to quality, we ensure you receive actionable insights ready for immediate use, empowering you to make informed decisions with confidence.
Why choose TagX Data Solutions
At TagX, we prioritize accuracy and reliability. Our data undergoes rigorous verification and regular updates to ensure you receive the most current and trustworthy information, enabling you to make informed decisions.
We understand that every business has unique data needs. TagX offers tailored data sourcing solutions designed specifically for your objectives, allowing you to gain insights that align with your strategic goals.
Our commitment to exceptional customer service means you’ll receive ongoing support whenever you need it. Additionally, TagX strictly adheres to data protection regulations, ensuring your data is sourced and managed responsibly.
Flexible Methods of Data Delivery
FLAT FILES
- Bulk Data Availability: Download comprehensive financial data sets in formats like CSV or Excel for offline analysis.
- User-Friendly: Easy to access and manage, making it ideal for users without technical expertise.
- Compatibility: Easily imported into various data analysis tools and software for further processing.
API
- Real-Time Data Access: Programmatically retrieve live financial data for immediate analysis and decision-making.
- Integration Capabilities: Seamlessly connect with your existing systems and applications for automated data retrieval.
- Customization Options: Tailor your data requests to fit specific needs, allowing for greater flexibility in how you use the data.
A data solutions company collects, processes, and delivers high-quality data to help businesses make informed decisions. TagX specializes in AI-driven data sourcing and processing across industries.
Data sourcing is the process of collecting structured and unstructured data from various sources like websites, databases, and APIs to support business intelligence and analytics.
We use automated validation, manual quality checks, and regular updates to ensure high-quality, reliable data.
Yes, we provide tailored data collection, processing, and delivery based on your industry and business needs.
Yes, we adhere to GDPR, CCPA, and other data protection laws to ensure secure and ethical data sourcing.
Simply contact us with your requirements, and our team will provide a customized data strategy to meet your goals.
Dubai, U.A.E.
Products
Services
Use Cases
Company
Copyright @2025 Inferentia L.L.C-FZ