
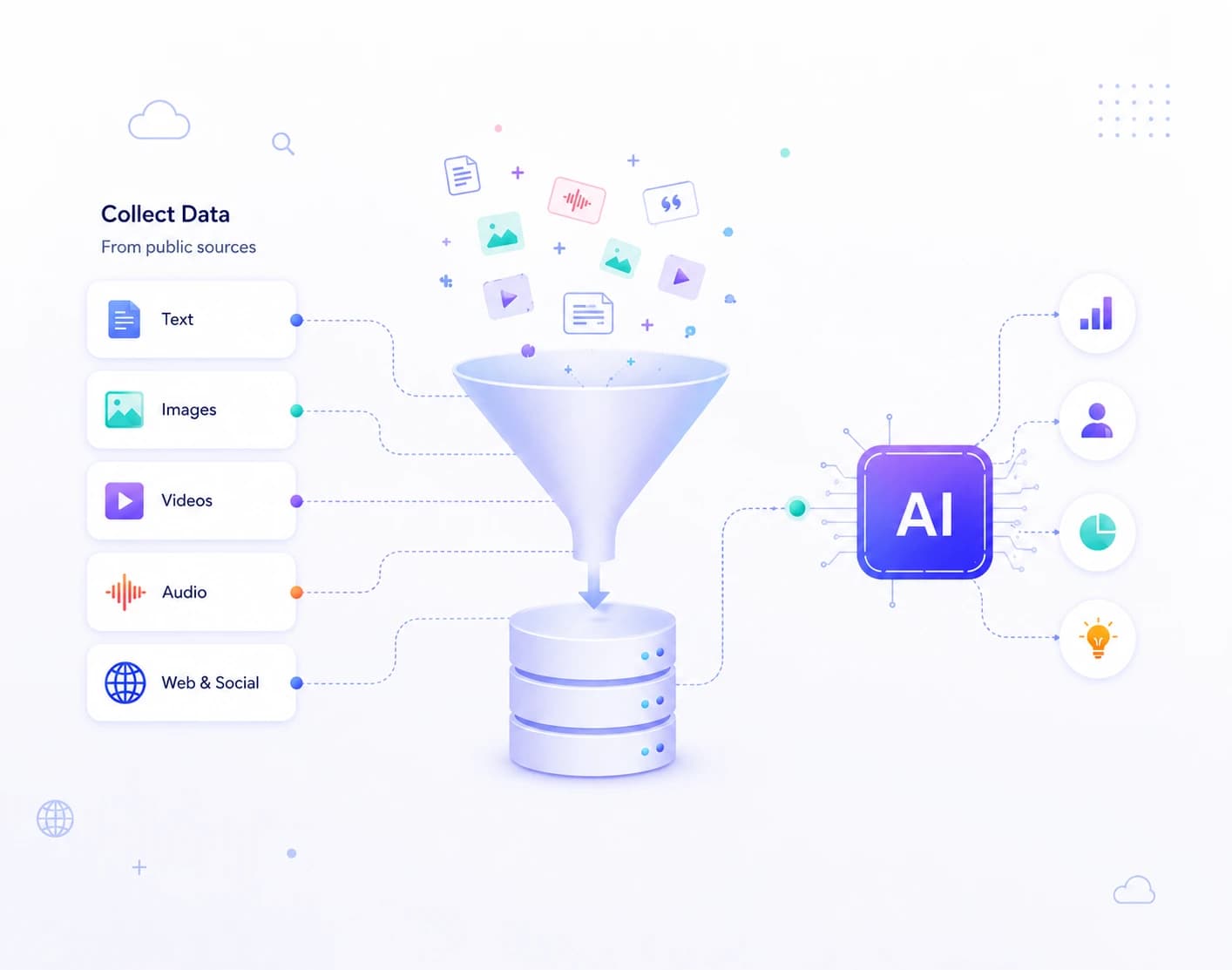
Up to 80% of AI development time is spent on data preparation - not model building. That's not a bottleneck. That's where the real work happens. The quality of your training data determines whether your model generalises or guesses, whether it responds accurately or hallucinates, whether it passes evaluation or fails in production.
TagX operates across the full AI data lifecycle - collection, curation, annotation, human feedback, and model evaluation. We don't just source datasets and deliver files. We build the ground truth data infrastructure your model depends on - with human-in-the-loop quality controls, domain-specific expertise, and the operational scale to keep pace with your training cycles.
Contact usAutomated labeling gets you volume; human-in-the-loop gets you accuracy. TagX combines both, using expert human reviewers to validate, correct, and quality-check every label before it enters your training pipeline.
Reinforcement Learning from Human Feedback aligns models with real-world expectations. TagX builds structured RLHF pipelines to collect, rank, and deliver high-quality human preference data.
Uncover real model weaknesses before deployment. TagX creates task-specific evaluation datasets and adversarial test sets that challenge your models, so you know exactly what needs improvement.
From text and video to specialized healthcare or legal data, TagX builds custom datasets reflecting your exact operational context—never generic web scrapes repackaged as training data.
Every AI model has a specific data requirement behind it, and the gap between a model that works in testing and one that performs in production is almost entirely determined by the quality of those inputs.
These are the six data services TagX delivers across the full AI training lifecycle.
Tell us your target data sources, required attributes, volume, and frequency. Whether you need a massive one-off scrape or live streams, we help refine your requirements into a bulletproof data brief tailored to your exact business logic.
We don't expect you to buy blind. We deliver a high-fidelity sample dataset in your preferred format (CSV, JSON) or set up a test API endpoint so your engineering team can instantly validate data quality, structure, and coverage.
Once you approve the sample, we finalize the scope, timelines, and SLAs. We map out the data delivery pipelines or configure your customized API access, making sure everything aligns perfectly with your technical infrastructure.
Our team handles the heavy lifting—managing proxies, bypassing anti-bots, and maintaining the infrastructure. We deliver clean, structured data directly to your cloud storage (S3, GCS) or serve it dynamically via production-ready APIs on your precise schedule.

From the first consultation to ongoing delivery, everything is completely managed by our engineering team.

Extract data at scale from websites across the globe. We bypass regional restrictions to deliver localised, market-relevant intelligence wherever your business operates.

Receive validated, structured data ready to plug directly into your systems or APIs — no manual cleaning, no reformatting, no friction.

Our pipelines run around the clock with proactive monitoring and dedicated support, so your data streams stay live, accurate, and uninterrupted.